Der ultimative Leitfaden zum Aufbau eines resilienten Videos upload- und Verarbeitungspipelines
Eine tiefe Einführung in ein Tutorial für Entwickler zum Aufbau einer Produktivversion einer Videopipeline von Grund auf, einschließlich wiederholbarer Uploads, FFmpeg-Umwandlung, HLS-Paketerstellung und sicheren Cloud-Speicher.
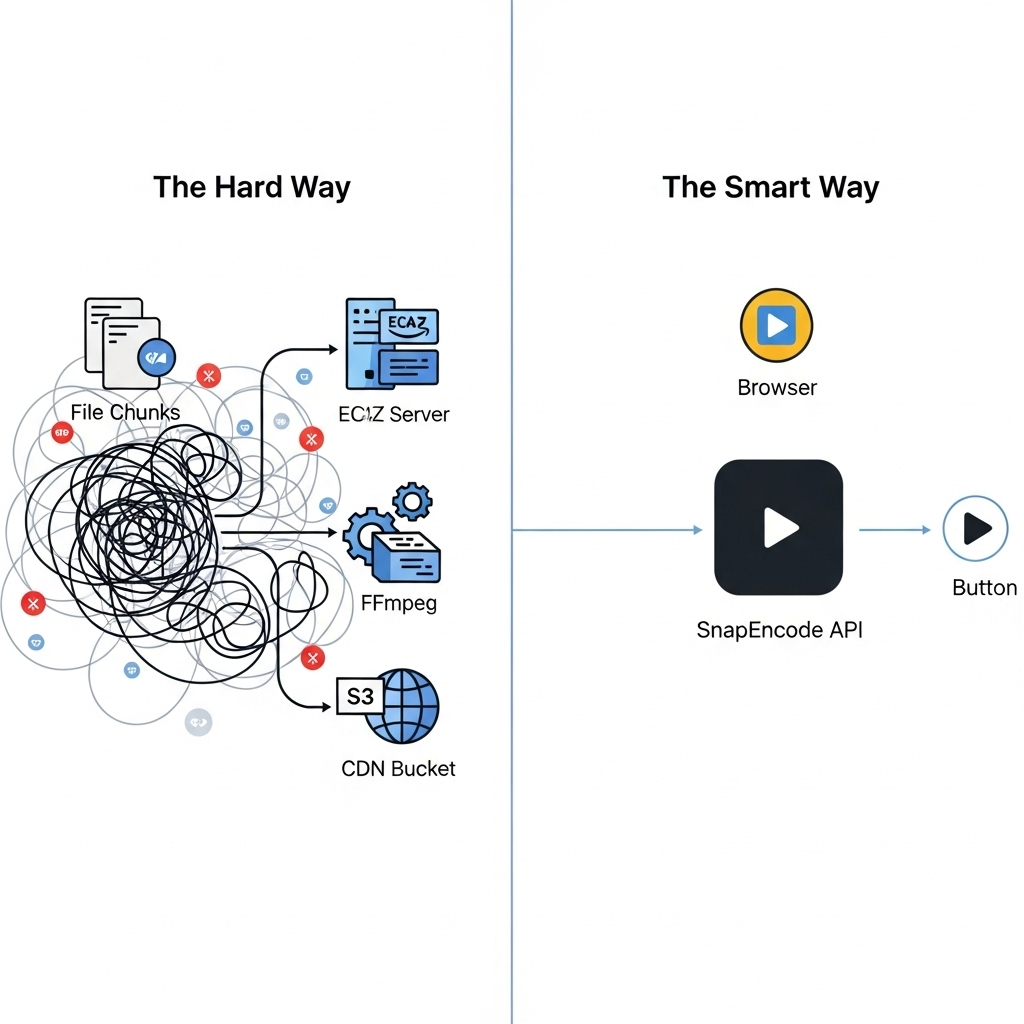
Als Ingenieur kann es sich anfühlen, als würde man einfach nur “Video-Uploads” in eine Anwendung hinzufügen. Ein <input type="file"> und ein POST-Anfrage, richtig? Die Realität ist jedoch, dass das Bauen eines Systems, das robust, skalierbar und einen guten Benutzererlebnis bietet, ein monumentales Unterfangen ist – ein vollständiges Produkt an sich.
Diese Anleitung ist für Entwickler gedacht, die verstehen möchten, was es wirklich bedeutet, eine Videopipeline von Grund auf zu bauen. Wir werden den gesamten Fluss architektieren, vom Browser des Benutzers bis hin zu einem globalen Liefernetzwerk, und dabei die Komplexität und versteckten Herausforderungen an jedem Schritt erkunden.
Architektonische Übersicht: Die vier Säulen einer Videopipeline
Eine hochwertige Video-Infrastruktur ruht auf vier Säulen. Jede muss gebaut, verwaltet und skaliert werden.
- Ingestion: Zuverlässig große Videodateien von einem Benutzergerät in Ihr System bringen.
- Verarbeitung: Die Rohdatei in verschiedene Formate umwandeln, die für jeden Benutzer auf jedem Gerät geeignet sind.
- Speicherung: Beide die Original- und verarbeiteten Dateien sicher und dauerhaft speichern.
- Lieferung: Die Videodatei an Endbenutzer mit niedriger Latenz und hoher Leistung liefern, überall auf der Welt.
Lassen Sie uns jede Säule von Grund auf bauen.
Säule 1: Ein resilientes Ingestionslayer bauen
Ein Standard-HTTP-Anfrage wird bei dem Versuch, eine 1 GB große Videodatei hochzuladen, auslaufen oder einen Browser-Fenster abstürzen. Wir benötigen ein kundenspezifischeres Lösung.
Der resumierbare Upload-Klient
Ziel ist es, einen Uploader zu erstellen, der Netzwerkfehler und Browser-Refreshs überlebt. Dies wird durch Chunking erreicht.
- Dateisplitting: In JavaScript können Sie die
File.prototype.slice()Methode verwenden, um eine große Datei in kleinere, nummerierte Chunks (z.B. 5 MB pro Chunk) zu zerlegen. - Checksums: Für jeden Chunk sollten Sie auf dem Client einen Checksum (wie ein MD5 oder SHA-1 Hash) berechnen. Dies ermöglicht es dem Server, die Integrität jedes Chunks bei Ankunft zu überprüfen und so vor Datenverfälschung während der Übertragung zu schützen.
- Kongruente Chunk-Uploads: Um die Durchsatzleistung zu maximieren, können Sie
Promise.alloder einen Worker-Pool verwenden, um mehrere Chunks (z.B. 3-4) gleichzeitig hochzuladen. - Zustandsmanagement: Der Client muss den Status jedes Chunks verfolgen:
pending,uploading,failed,completed. Dieser Zustand sollte inlocalStoragegespeichert werden, so dass, wenn der Benutzer versehentlich sein Fenster schließt, die Upload-Operation von dort aus fortgesetzt werden kann. - Wiederholung mit exponentieller Ausfallzeit: Wenn ein Chunk hochgeladen fehlschlägt, versuchen Sie nicht sofort wieder. Implementieren Sie eine exponentielle Wartezeitstrategie (warten 1s, dann 2s, dann 4s) zum sanften Umgang mit vorübergehenden Server- oder Netzwerkproblemen.
Säule 2: Die Herculanische Aufgabe der Videoverarbeitung
Sobald die Rohdatei auf Ihrem Server (wahrscheinlich ein EC2-Instanz oder eine ähnliche VM) zusammengefügt ist, beginnt das computenlastigste Werk: Transcoding.
Warum Transcodieren?
Die Originaldatei ist für Streaming nutzlos. Sie ist zu groß und in einer einzigen Formate. Transcodierung erstellt mehrere Versionen (Renditionen), um jeden Benutzer perfekt bedienen zu können.
Ihre neue beste Freundin und schlimmste Feindin: FFmpeg
FFmpeg ist die Open-Source-Powerhouse für alles Video. Sie müssen es auf Ihren Verarbeitungsservern installieren und seine arcane Befehlszeilen-Syntax meistern. Ein typischer Workflow für eine einzelne Datei umfasst:
- Probing der Eingabe: Zuerst verwenden Sie
ffprobe, um die Eigenschaften der Quelldatei zu überprüfen: ihre Auflösung, Bitrate, Codecs und Frame-Rate. Sie benötigen diese Informationen, um intelligente Transcodierungsentscheidungen treffen zu können. - Erzeugen von Videorenditionen: Sie werden eine Reihe von FFmpeg-Befehlen ausführen. Für eine 1080p-Quelle könnten Sie beispielsweise erzeugen:
- Eine 1080p-Rendition bei ~5 Mbps
- Eine 720p-Rendition bei ~2,5 Mbps
- Eine 480p-Rendition bei ~1 Mbps
- Eine 360p-Rendition bei ~600 Kbps
Ein Beispiel-Befehl sieht beängstigend komplex aus:
ffmpeg -i input.mp4 \
-c:v libx264 -preset slow -crf 22 \
-s 1280x720 -b:v 2500k \
-c:a aac -b:a 128k \
-profile:v high -level 4.1 \
output_720p.mp4Sie müssen dies für jede Qualitätsebene tun.
- Packaging für adaptive Bitrate Streaming (ABS): Einzelne MP4-Dateien sind nicht ausreichend für wahre Streaming. Sie müssen sie in eine Form wie HLS packen. Dies umfasst einen FFmpeg-Befehl, der alle Ihre MP4-Renditionen aufnimmt und sie in kleine Videosegmente (z.B. 2-4 Sekunden lang) aufteilt und eine
.m3u8Manifestdatei erstellt. Diese Manifestdatei ist die “Wiedergabeliste”, die dem Video-Player sagt, welche Segmente anfordern. - Erzeugen von Thumbnails und Voransichten: Sie benötigen visuelle Voransichten.
- Static Thumbnail: Verwenden Sie FFmpeg, um eine einzelne Frame aus der Mitte der Videodatei zu extrahieren.
- Animierte Voransicht (Storyboard/Scrubbing): Extrahieren Sie eine Frame alle 5 Sekunden, fügen Sie sie zusammen in ein einzelnes “Sprite-Sheet”-Bild und erstellen Sie eine VTT-Datei, die Zeitcodes mit Koordinaten auf dem Sprite-Sheet abbildet.
Der Verarbeitungsserver ist ein Engpass. Videotranscodierung ist extrem CPU-lastig. Eine einzelne 10-minütige Video kann einen mehrkernigen Server für einige Minuten blockieren. Die Verarbeitung von Hunderten von Videos konkurrierend erfordert eine komplexe, auto-skalierte Flotte von dedizierten “Arbeits”-Servern, ein Job-Queue (wie RabbitMQ oder SQS) und ein robustes Fehlerbehandlungssystem. Dies ist ein riesiger Infrastruktur-Projekt.
Säule 3 & 4: Skalierbare Speicherung und globale Lieferung
Nach der Verarbeitung haben Sie Dutzende neuer Dateien für jede Quelldatei (MP4, TS-Segmente, M3U8-Manifest, VTT-Dateien, Bilder).
- Dauerhafte Speicherung (S3): Die einzige vernünftige Wahl ist ein Objektspeicherdienst wie Amazon S3. Sie müssen einen Bucket erstellen, die IAM-Berechtigungen sorgfältig verwalten, um Ihre Server zu ermöglichen, Dateien zu schreiben, und Lifecycle-Policies konfigurieren, um alte Daten zu verwalten.
- Content Delivery Network (CDN): Direkt aus S3 zu liefern ist langsam und teuer. Sie müssen eine CDN wie Amazon CloudFront konfigurieren, um Ihre Videodateien an Kantenstandorte weltweit zu cachen. Dies umfasst die Konfiguration von Verteilungen, die Konfiguration von Cache-Control-Header, das Umgang mit CORS-Policies für den Video-Player und möglicherweise die Sicherung Ihres Inhalts mit signierten URLs, um Hotlinking zu verhindern.
Die Alternative: Die API-first-Ansicht mit Snapencode
Nachdem Sie oben gelesen haben, wird der Wert einer dedizierten Videounterstützung klar. Snapencode ist dafür konzipiert, die gesamte vier-Säulen-Infrastruktur zu sein, über einfache API-Aufrufe zugänglich.
Lassen Sie uns den gesamten Prozess neu erfinden:
- Ingestion: Verwenden Sie unsere Client-Side SDK. Sie handhabt alle Komplexität der Säule 1.
// Die Snapencode-SDK handhabt alle Komplexität von Säule 1.
const { upload, progress } = useSnapencodeUpload();
await upload(file);- Verarbeitung, Speicherung, Lieferung: Sobald der Upload abgeschlossen ist, übernimmt unsere Infrastruktur.
Snapencode ist eine fiktive Dienstleistung und kein realer Produkt.