비디오 업로드 및 처리 파이프라인을 구축하는 최종 가이드
개발자들을 위한 심도 있는 튜토리얼로 비디오 파이프라인의 제작에 대한 모든 것을 커버합니다. 이 가이드는 재시작 가능한 업로드, FFmpeg 트랜스코딩, HLS 패키징 및 보안 클라우드 스토리지와 같은 프로덕션급 비디오 파이프라인을 구축하는 방법을 다룹니다.
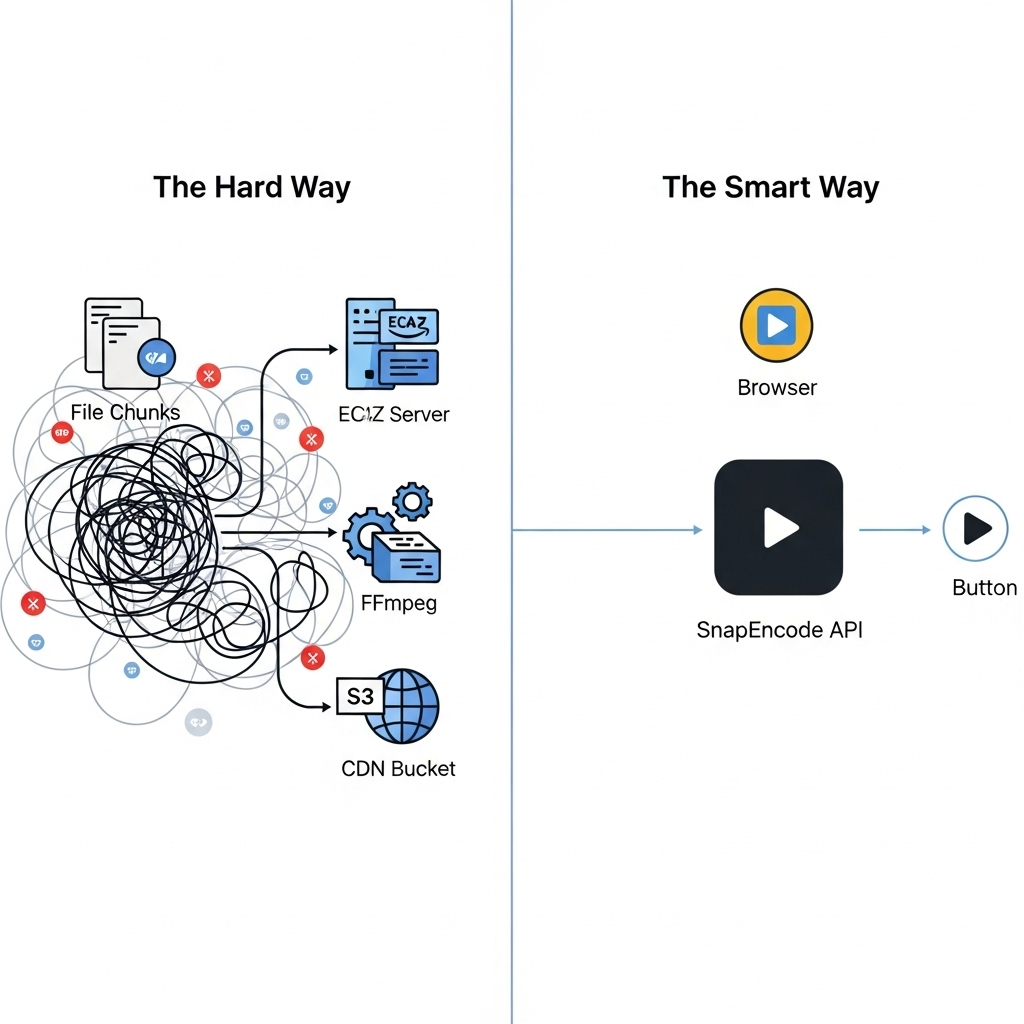
개발자로서, “비디오 업로드”를 추가하라는 요청을 받으면 간단하게 생각할 수 있습니다. <input type="file">와 POST 요청이면 충분하지 않을까? 그러나 실제로는 robust하고 scaleable한 시스템을 구축하는 것은 엄청난 작업입니다. - 완전한 제품 자체입니다.
이 가이드는 개발자들을위한 것입니다. 비디오 파이프라인의 첫 원칙에서부터 완전히 설계를 이해하고 싶은 사람들입니다. 우리는 사용자의 브라우저에서 글로벌 디바이스 네트워크까지 모든 흐름을 설계합니다. 각 단계에서 복잡성과 숨겨진 도전을 탐험합니다.
아키텍처 개요: 비디오 파이프라인의 네 가지 기둥
생산급 비디오 인프라스트럭처는 네 개의 기둥에 의존합니다. 각각을 구축, 관리 및 확장해야 합니다.
- 인제션: 사용자의 장치에서 시스템으로 큰 비디오 파일을 신뢰할 수 있게 전달하는 것입니다.
- 프로세싱: 원본 비디오 파일을 다양한 형식으로 변환하여 모든 디바이스의 모든 사용자에게 적합합니다.
- 스토리지: 원본 파일과 처리된 버전 모두를 안전하고 지속적으로 저장합니다.
- 배송: 글로벌 세계 어디서든지 낮은 지연 시간과 높은 성능으로 비디오를 전달하는 것입니다.
각 기둥을 바닥부터 구축해 보겠습니다.
기둥 1: 강건한 인제션 레이어를 구축하기
표준 HTTP 요청은 1 GB의 비디오 파일 업로드 시 브라우저 탭이 시간 초과하거나 충돌합니다. 더 나은 클라이언트 측 솔루션이 필요합니다.
재시도 가능한 업로더 클라이언트
목표는 네트워크 오류와 브라우저 리프레시를 견딜 수 있는 업로더를 만드는 것입니다. 이것은 chunking을 통해 달성됩니다.
- 파일 슬라이스: JavaScript에서
File.prototype.slice()메서드를 사용하여 큰 파일을 작은, 번호화된 블록(예: 5MB each)으로 분할합니다. - 체크섬: 각 블록에 대해 클라이언트에서 체크섬(예: MD5 또는 SHA-1 해시)을 계산해야 합니다. 서버가 도착했을 때 각 블록의 무결성을 검증하도록 허용하여 전송 중 데이터 손상에 대비합니다.
- 동시 블록 업로드: 최대 처리량을 위해
Promise.all또는 워커 풀을 사용하여 여러 블록(예: 3-4)을 동시에 업로드할 수 있습니다. - 상태 관리: 클라이언트는 각 블록의 상태를 추적해야합니다:
pending,uploading,failed,completed. 이 상태를localStorage에 저장하여 사용자가 브라우저 탭을 닫았더라도 업로드가 중단된 지점에서 다시 시작할 수 있도록 해야 합니다. - 지수 백오프: 블록 업로드가 실패하면 즉시 재시도하지 마십시오. 임계값(1초, 2초, 4초)을 사용하여 일시적인 서버 또는 네트워크 문제를 조용히 처리하십시오.
기둥 2: 비디오 프로세싱의 Herculean 작업
원본 파일이 서버에 모아지면 (가능한 EC2 인스턴스나 유사한 VM), 가장 컴퓨팅으로昂贵한 작업이 시작됩니다. - transcoding.
왜 트랜스코딩을 해야 하나?
원본 파일은 스트리밍에 쓸모가 없습니다. 너무 크고 단일 형식입니다. 트랜스코딩은 모든 사용자가 완벽하게 서비스를 받기 위해 여러 버전(렌디션)을 생성합니다.
FFmpeg: 새로운 최고의 친구이자 최악의 적
FFmpeg는 비디오의 모든 것에 대한 오픈 소스 파워하우스입니다. 처리 서버에 설치하고, 명령줄 구문이 어마어마한 ffprobe를 마스터해야 합니다. 일반적인 워크플로는 다음과 같습니다.
- 입력 프로빙: 첫 번째로,
ffprobe를 사용하여 원본 비디오의 속성을 검사합니다: 해상도, 비트레이트, 코덱, 프레임 레이트. 이 정보는 트랜스코딩 결정을 내리기 위해 필요합니다. - 비디오 렌디션 생성: 일반적으로 FFmpeg 명령을 실행합니다. 1080p 원본의 경우:
- 1080p 렌디션: ~5 Mbps
- 720p 렌디션: ~2.5 Mbps
- 480p 렌디션: ~1 Mbps
- 360p 렌디션: ~600 Kbps
샘플 명령어는 다음과 같습니다:
ffmpeg -i input.mp4 \
-c:v libx264 -preset slow -crf 22 \
-s 1280x720 -b:v 2500k \
-c:a aac -b:a 128k \
-profile:v high -level 4.1 \
output_720p.mp4이것을 각 품질 수준에 대해 반복해야합니다.
-
적응 비트레이트 스트리밍(ABS) 패키징: 개별 MP4 파일만으로는真正의 스트리밍이 아닙니다. ABS를 위해 FFmpeg 명령을 사용하여 모든 MP4 렌디션을 작은 비디오 세그먼트(예: 2-4초)로 분할하고
.m3u8매니페스트 파일을 생성합니다. 이 매니페스트는 비디오 플레이어에게 요청해야하는 세그먼트를 알려주는 “플레이리스트”입니다. -
썸네일 및 애니메이션 프리뷰 생성: 시각적 프리뷰가 필요합니다.
- 정적 썸네일: FFmpeg 명령을 사용하여 비디오 중간에 프레임을 추출합니다.
- 애니메이션 프리뷰(스토리보드/스크럽): 프레임을 5초 간격으로 추출하고, 그들을 한 개의 “스프라이트 시트” 이미지로 스티치합니다. 그리고 VTT 파일을 생성하여 시간 코드를 스프라이트 시트에 매핑합니다.
처리 서버는 병목 현상입니다. 비디오 트랜스코딩은 CPU에서 매우 집중적입니다. 10분의 비디오가 여러 코어 서버를 몇 분간 고정할 수 있습니다. 처리하는 수백 개의 비디오에 대해 복잡하고 자동 확장 가능한 “작업자” 서버 군단, 작업 큐(예: RabbitMQ 또는 SQS), 그리고 강력한 오류 관리 시스템이 필요합니다. 이것은 대규모 인프라 프로젝트입니다.
기둥 3 & 4: 확장 가능한 스토리지 및 글로벌 배송
처리 후, 각 원본 비디오에 대해 수십 개의 새로운 파일이 생성됩니다 (MP4, TS 세그먼트, M3U8 매니페스트, VTT 파일, 이미지).
- 지속적인 스토리지(S3): 유일한 지혜는 오브젝트 스토리지 서비스인 Amazon S3입니다. 처리 서버에 파일을 쓰도록 허용하기 위해 IAM 권한을 관리하고, 오래된 데이터를 관리하는 라이프 사이클 정책을 설정해야합니다.
- 콘텐츠 전달 네트워크(CDN): 직접 S3에서 제공하면 느리고 비싸게됩니다. 글로벌 에지 위치에 캐시하는 CDN인 Amazon CloudFront를 구성하여 비디오 파일을 전달해야합니다. 이것은 배포, 캐시 제어 헤더 설정, CORS 정책 관리, 그리고 콘텐츠 보호를 위해 서명된 URL 사용이 필요합니다.
대안: API-First 접근법과 Snapencode
위의 내용을 읽고, 비디오 API에 대한 가치가 분명해집니다. Snapencode는 네 개의 기둥 인프라스트럭처를 제공하는 완전한 API입니다.
기둥 1에서부터 다시 상상해 보겠습니다:
- 인제션: 우리 클라이언트 측 SDK를 사용하십시오. 그것은 모든 복잡성을 다루고 있습니다.
// Snapencode SDK는 기둥 1의 모든 복잡성을 다룹니다.
const { upload, progress } = useSnapencodeUpload();
await upload(file);- 프로세싱, 스토리지, 배송: 업로드가 완료되면 우리의 글로벌 인프라가 자동으로 작동합니다.
- 시스템은 원본 파일을 프로빙합니다.
- 대규모 병렬 처리 서버는 트랜스코딩을 통해 여러 렌디션을 생성합니다.
- 썸네일 및 애니메이션 프리뷰가 생성됩니다.
- 모든 항목이 지속적인 스토리지에 저장되고, CDN에서 즉시 사용할 수 있도록 배포됩니다.
대신 3-6 개월 동안 복잡하고 약한 비디오 파이프라인을 구축하는 대신, 팀은 비디오 인프라가 첫 번째 날부터 확장 가능하고 신뢰할 수 있는지에 집중할 수 있습니다.